

- By Edward Marszal
- January 30, 2020
- InTech
Summary
Fast Forward
- Relational databases are becoming obsolete for PHA, as Internet technology like cloud computing brings new and better ways to store and work with data.
- As industry migrates to an Internet technology paradigm, best practices from the IT world, including unified data structures, XML, and JSON, become more important.
- The unified hazard assessment data structure provides a platform where a single data set can be used for multiple purposes.
Internet technology can unite PHA, HAZOP studies, LOPA, and hazard registers

By Edward M. Marszal
Process hazards analysis (PHA) studies, especially hazards and operability (HAZOP) studies and layer of protection analysis (LOPA) reports are ubiquitous in the process industries, but the information generated during these studies is not being used to its fullest extent. Management desires to have multiple scenarios rolled up into easier-to-use hazard registers, and to be able to visualize them with graphical approaches like bow-tie diagrams. Unfortunately, the data that is currently contained in most HAZOP and LOPA studies is not structured to allow easy hazard register generation and bow-tie visualization. The use of the “cause local – consequence global” approach to HAZOP has made the facilitator’s life easier at the expense of others who need PHA data but cannot find what they need because the resulting documentation is not logical.
This article discusses the use of standardized data structures that are already revolutionizing PHA documentation. Extending these standardized data structures will allow the development of tools that can display a single set of data as a HAZOP worksheet, LOPA worksheet, or bow-tie diagram. Furthermore, the hazard analysis can be modified using any of these visualization techniques and have the results carried back across all diagram and worksheet types. Adoption of a unified hazard assessment data structure will benefit all users of PHA data and facilitate use of PHA data by other critical stakeholders, automatically.
Process hazards analysis
Chemical process facilities spend considerable resources on process hazards analysis studies. Initially, many organizations performed PHA in a minimal-cost, minimal-compliance fashion, in order to “check the box” for regulatory compliance. Many bad habits were formed in this early phase of PHA adoption that are still with us today, but which can hopefully be rectified with a combination of better software and better motivated PHA facilitators. Since the early adoption phase of PHA, many sophisticated organizations not only committed to the PHA process, but also expanded the use of PHA information, leveraging the information for engineering and management tasks that were performed by other process stakeholders. One of the first extensions of PHA information was LOPA.
Beyond LOPA, managers of process plants were interested in summarizing the information from PHA into lists of significant hazards. These managers would regularly refer to these hazard lists and ensure that all of the safeguards affecting the risk of these scenarios were properly designed, implemented, and maintained. These lists of significant hazards and information relating to them are typically referred to as hazard registers. While hazard registers became a powerful tool for managing risk, understanding the hazards and communicating them throughout the organization and even to external stakeholders was difficult due to the highly technical nature of the information and the dense use of acronyms and jargon.
Bow-tie diagrams
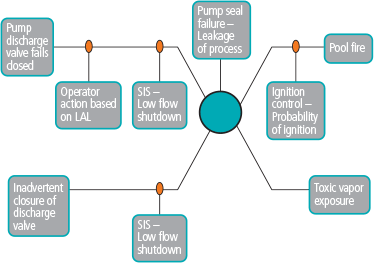
To aid in the understanding of hazard scenarios, the visualization technique of bow-tie diagrams was developed. When a hazard scenario is visualized as a bow-tie diagram, it is a graphical representation of the development of the scenario. The bow-tie diagram reads from left to right (figure 1). On the left a series of causes of the hazardous event are listed. A line is drawn from each cause to the “knot” in the bow tie.
The knot in the bow tie represents the realization of the hazardous event. In the process industries the “knot” is typically a loss of containment of process chemicals. Along each line from the cause to the bow-tie knot are “barriers.” Barriers are events, systems, or situations that prevent the cause from resulting in the loss of containment scenario—which in bow-tie analysis jargon is typically referred to as the hazard or hazardous event. Barriers between the cause and the loss of containment are referred to as “preventive” barriers as their successful operation prevents the loss of containment from occurring.
On the right side of the bow-tie knot is the description of what occurs after the loss of containment. This consists of a series of consequences that can occur as a result of the loss of containment event, with lines drawn from the “knot” to the consequences. As with the causes, all of the consequences may have barriers that will either prevent or mitigate (i.e., reduce the magnitude of) the consequence if they operate effectively.
The key benefit of the presentation of a risk scenario as a bow-tie diagram is that the visualization accelerates and facilitates understanding of the scenario. The combination of the visual cues and textual information is a much richer representation of the hazard scenario information.
The preceding discussion clearly shows that there are myriad valuable uses for the information developed during PHA. It would seem that you should be able to simply press a button, and switch from viewing the data as a PHA to viewing it as a LOPA, then a hazard register, and finally as a bow-tie diagram. Further, it seems like you should be able to make edits to the bow-tie diagram and have them cascade back to the LOPA study, and then you should also be able to view the quantitative aspects of the LOPA while you are viewing the bow-tie diagram.
Unfortunately, this is not currently the case. At the current moment, each of these different uses of PHA data use different software applications, each of which use different data structures to represent data. Even worse, the data structures in the different applications for different study types are completely and irreconcilably different from each other such that data cannot be shared between applications.
To address this situation and maximize the utility of the data that the process industries are investing in, a few changes need to be made in how PHA is performed and documented. First, a change in the mindset about how PHA facilitators document studies will be required. Facilitators must be willing to document studies based on where the hazard manifests itself as opposed to the location of the cause of the hazardous event. But most importantly, industry needs to move to a common, consistent, standardized data structure for PHA: the unified hazard assessment.
Basics of structuring data
Before delving specifically into the problem of defining a consistent structure for PHA data, we should begin by discussing how data is structured in general. Although this section will rely on terminology that was developed for relational databases, it is applicable to other methods of data storage and retrieval that are vastly superior to the use of traditional relational databases for hazard analysis studies.
The primary concepts of relational databases for storing data are tables, records, fields, relationships, and identifiers (IDs). A table is a structured list of data that all describe a given item; for instance, a PHA study will generally have a table that describes all of the study nodes. The best way to think about a data table is by visualizing a spreadsheet. A table contains many rows and columns of information where each column of information is a specific piece of information, such as a node number or a node description.
A database generally contains many different tables that describe the different aspects of a system. For example, a PHA database might contain a table for nodes, deviations, and causes. The reason that different tables are required is because, often, there are multiple instances of one type of item that all relate to a single instance of another. With PHA, for instance, a single node will have many different deviations associated with it, and a single deviation can have many causes. To address this phenomenon, we set up multiple tables of information, and organize the linking between the tables using relationships.
In database science there are three types of relationships: one-to-many, many-to-one, and many-to-many. A one-to-many relationship means that for a single item in the primary table, there can be many items in the secondary table that are associated. In other words, the primary table, the “parent” in the relationship, can have many “children” in the secondary table. In a typical PHA, a single node has many deviations, and each deviation has many causes. A relational database manages these relationships first by understanding how they are defined, and then by tracking the IDs of the records.
Cause indexing
When you look at a PHA report, a single deviation contains multiple rows that contain causes of the deviation. Although it looks like a single table to the viewer, in reality the software is combining the two different tables into one visualization. The deviation table, in fact, does not actually contain any information about causes at all! Instead, each cause contains the identifier (ID) of the deviation that it is associated with.
This activity is referred to as cause indexing. What the PHA software does in order to display that view that most of us are familiar with is to first display the deviation from the deviation table and subsequently search the causes table to find all of the causes that are associated with a given deviation. It does this by comparing a “Deviation ID” field in each cause record with the ID of the deviation that is currently being displayed.
A many-to-one relationship is the opposite of one-to-many and works very similarly. A many-to-many relationship between tables is the most complex situation. Here, a single record in the primary table can have multiple associated records in the secondary table, but, individual items in the secondary table can also have relationships with multiple records in the primary table. The best example of this in PHA is recommendations. Each PHA cause (scenario) can have multiple recommendations associated with it, but each of those recommendations can also be associated with multiple causes.
In this complex case, an entirely separate table needs to be created simply to store the relationships between the primary and secondary table. As alluded to earlier, each table contains multiple records. Each record is like a row on a spreadsheet and contains all of the different attributes of a specific entry on the table. Each record then is composed of multiple different fields. Each field is a specific data entry of a given data type.
For instance, if a PHA study contains a table of safeguards, that table might contain individual fields for tag (text string), description (text string), probability of failure on demand (floating point number), effectiveness determination (Boolean), and ID (GUID). All of these structures combined together result in the overall database structure.

Relational database challenges
The discussion in the preceding section used terminology that is consistent with relational database technology, which is commonly used to store PHA data. However, use of relational databases is becoming obsolete in applications like PHA studies, as Internet technology and cloud computing offer better ways to store and work with data. All of industry, and all of society, is migrating to a paradigm where information is stored in the cloud, and all knowledge work will be performed by interacting with the cloud, generally through a web browser. Even when desktop applications are developed today, they are generally a thin wrapper that essentially holds a web page.
Relational databases accessed through the cloud work great when the user would like to interact with a single record of a single table in a database. But, when a user desires to work with and view multiple different records of multiple different tables, the result is a dreadful and slow user experience, as the web page tries to kludge up a concatenation of all the requested information in a single form. This form then updates every time the user shifts focus from one element to another—especially if anything was edited, because that is what is required to maintain contact with the database server.
The primary problem is the transactional nature of a relational database. When a user requests a piece of information, the database must know specifically what table, record, and field to get. It then grabs that piece of information, transfers the data between server and client, and the client processes the information by presenting it on the screen.
As described in the previous section, in order to present a PHA worksheet on a computer screen, data needs to be obtained from multiple fields, in multiple records, of multiple tables. Furthermore, drawing the information on the screen is complicated by the fact that the application needs to change the view as a function of how many records in secondary tables are associated with a given record in a primary table. This requires thousands (or even tens of thousands) of individual database transactions to occur between the client and server to obtain the information for a single screen view.
The problem is usually further exacerbated by third-party “controls” used during the programming process. Many software vendors do not have the talent to directly access the database, and instead rely on third-party controls that they configure to access the desired data. Unfortunately, these controls—such as text boxes and grids—have bloated and slow code, because they are designed to be flexible, not fast.
A new paradigm
The elite companies in Silicon Valley have developed better ways to handle this problem and are using them frequently and widely in their software and web sites. Unfortunately, most PHA software has not caught up with the times. The state-of-the art approach is to eschew traditional relational database technology in favor of the flexible data object models that were born in cloud computing. Specifically, the data transaction speed problem was solved using Extensible Markup Language (XML) and subsequently its even lighter cousin JavaScript Object Notation (JSON).
In the new paradigm, when a web page wants to get data from a database server, it does not request a single field at a time, it requests that a large collection of data is “serialized” into a JSON object, and that single object is conveyed from server to client in a single transaction. As a result, a best-in-class, cloud-based PHA application only communicates with the server twice per worksheet—once to load the data from the server, and then once again to return the edited data back to the server. In the interim, the web page keeps the entire data object in memory on the client. When users interact with the data, they are interacting with the data on the client—at lightning speed—not the data on the server.
New data structures like XML and JSON have all the advantages of a relational database. They can easily store multiple tables, each with multiple records and multiple fields. They can also manage relationships between tables, in all formats, the same way that relational databases do. Figure 2 presents an example of some PHA data being stored as a JSON object.
While some applications are built with a relational database server that serves up the data to build a web page and then stores the results after the page is edited, more and more, the relational database is not used at all. The JSON objects are simply stored on the server as the end result.
Unified hazard assessment
A single data structure cannot be both cause indexed, as is the most common approach for HAZOP, and also consequence indexed, as is the most common approach for LOPA. Furthermore, neither of these data structures is suitable for hazard registers or bow-tie diagrams. But the latter two are indexed by a “hazard” or a “hazard scenario”— the approach that also underlies a unified hazard assessment data structure.
The unified hazard assessment data structure provides a platform that allows a single data set to be used for multiple purposes. HAZOP studies can generally be performed using the same workflow as always, but you need to take some additional care where things are documented. Also, at least one additional data field will need to be completed, or at least separated out of the cause or consequence description, where it usually resides. With regard to data structure, the HAZOP worksheet needs to show, for each deviation, one or more hazard scenarios. Each hazard scenario can show multiple causes and multiple consequences. Other than that, the PHA worksheet will look essentially the same.
Once the HAZOP has been documented using the unified hazard assessment approach, development of the LOPA is dramatically simplified. The data structure for each hazard scenario record should include a Boolean variable that indicates whether or not the hazard scenario requires a LOPA. In this way, when the user starts by viewing the HAZOP study, he or she should be able to click on a single tab or button and have the software automatically redraw the user interface for LOPA.
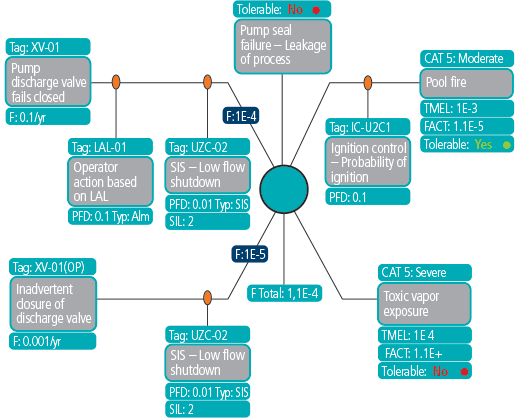
There is an even more powerful aspect to bow-tie diagrams using the unified PHA format. Currently, most bow-tie diagrams are simply a visual representation of a hazard scenario, but with an underpinning of a unified hazard assessment data structure, the bow-tie diagram can include all the quantitative aspects, such as the frequency of the initiating event, the safeguard probability of failure on demand, and the overall scenario frequency and risk ranking. This will enable performing a HAZOP or LOPA using the graphical format of the bow-tie diagram (figure 3).
The last information presentation format that needs to be addressed is the hazard register. This is the easiest of all the problems to solve after the development of the unified hazard assessment data structure. Basically, the data that is developed in a HAZOP worksheet is sufficient to meet this need, as long as it is hazard-scenario indexed. In fact, one might want to limit the data presented to even less than what is shown in a HAZOP worksheet.
Unified hazard assessment is a method to restructure and optimize PHA data so that it can be used for more than just process safety management compliance. A standardized unified hazard assessment data structure and complaint methods for documenting PHA data allow a single data set and a single software tool to be able to seamlessly present data as PHA (HAZOP), LOPA, hazard register, and bow-tie diagrams.
This article was adapted from a paper originally published for the Texas A&M Engineering Experiment Station’s Mary Kay O’Connor Process Safety Center 22nd annual international symposium, held 22 – 24 October 2019. Read this article online for a link to the full paper.Reader Feedback
We want to hear from you! Please send us your comments and questions about this topic to InTechmagazine@isa.org.