

- By Vibhoosh Gupta
- Factory Automation
Summary
Fast Forward
- Controller redundancy provides many benefits as part of any high-availability strategy for factory automation and machine control.
- Traditionally, controller redundancy schemes introduced performance limitations and were complex and expensive—so they were used for only the most crucial applications.
- Today’s technologies offer a much better controller redundancy price/performance ratio, but users must understand the implementation details to ensure they receive the expected ROI.
Industrial controller redundancy improves system availability, but only if it is implemented with the right capabilities.

In many cases, conventional wisdom tells us that if one is good then two are better. This concept extends to the design of industrial automation systems. Even though industrial programmable logic controllers (PLCs) are very reliable, they are a single point of failure susceptible to onboard faults, as well as external problems with power or networking. For critical applications, designers must consider how to address this issue, usually by implementing a secondary backup or redundant PLC.
A more general and encompassing discussion is how to achieve high availability (HA) for industrial automation platforms. Providing an HA system requires eliminating as many single points of failure as possible. Redundancy, either as parallel systems or as multiple systems that can take over for failed systems, is a primary strategy for HA designs. And if redundancy can be easily and cost effectively accomplished while preserving the necessary performance level, it becomes useful and desirable for many more machine automation applications. While the primary goal of redundancy is usually around-the-clock availability, many users rely on redundancy to help them perform maintenance during normally scheduled operating hours without affecting production.
It is tempting to assume that all factory automation redundancy solutions provide the same benefits, but upon inspecting the details it soon becomes clear that all solutions are not the same. For controllers and control systems used for factory and machine automation, attention to controller redundancy implementation details is crucial to understanding their effectiveness.
All redundant industrial controllers do not behave exactly alike. There are many implementation design choices affecting the performance, timing, and supportability of redundant controller solutions, and end users must carefully weigh these details before committing to a deployment.
Edge to enterprise redundancy
Redundancy at all levels of automation is justified by the return on investment (ROI). Users must recognize any costs of equipment, setup, commissioning, and maintenance versus the benefits of operational availability, flexibility of maintenance scheduling, and better diagnostics (figure 1). 
Redundant systems are generally preferred over nonredundant (simplex) systems, with a few caveats. Some redundant implementations increase complexity, driving up the design, hardware, and operational costs beyond what is justified. Also, some redundancy methods compromise various aspects of performance and are therefore unsuitable.
When considering a redundancy solution for any application, multiple automation disciplines must be evaluated in relationship with each other to ensure the expected performance will be delivered:
- power distribution
- instrumentation
- fieldbus networks
- industrial controller
- on-site PCs
- information technology (IT) networks
- cloud connectivity
- cloud computing.
Redundant devices powered from a single fallible circuit do not have the best reliability. Redundant instruments provide more data but raise the question of which signal is correct. Fieldbus and IT networks in a ring configuration are a good redundancy choice, if designers route the cabling carefully so a physical break opens the ring in only one location. Many cloud resources have redundancy features, but poor connectivity can compromise them.
This article focuses on HA redundancy factors for industrial controllers, such as programmable logic controllers and edge controllers. These controllers interact in several ways with other devices, connecting:
- down to lower-level field devices and instruments
- up to higher-level human-machine interface (HMI) and supervisory control and data acquisition (SCADA) systems
- laterally to other peer controllers.
Due to expense and complexity, industrial automation redundancy has largely been reserved for only the most critical processes in past years. However, advances with hardware, software, and networking have made it far more practical to incorporate controller redundancy into machine automation applications of all types.
Basic controller redundancy architectures
Controller redundancy architectures for delivering HA typically involve paired controllers, although more controllers are possible for the most crucial applications. 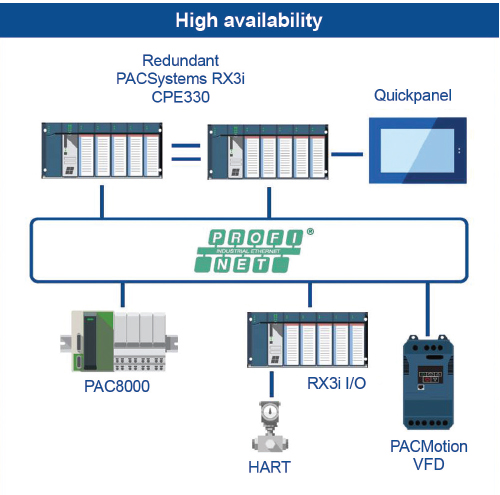
The primary controller operates the input/output (I/O), and it executes control logic and communication tasks. Physical I/O and other smart devices are arranged on one or more fieldbus network ring for access by both processors (figure 2).
Also, the primary controller must continually update or mirror itself to the secondary regarding the I/O status, memory values, and any program changes, so the secondary is ready to assume control seamlessly if needed (figure 3).
In the event of a major fault—such as a power failure, cut cable, rack fault, or processor error—the primary controller switches over to the secondary, which should seamlessly continue with operation. This action is known as switchover or failover. 
Another scheme called warm standby indicates that a secondary controller may be installed, powered, or at least preloaded, but may not be synchronized and may require user intervention to initiate a switchover. This introduces significant delay and might only be acceptable for simpler systems. For instance, if a production line has many machines in parallel, the loss of one line for a short time may not be debilitating.
The lowest performance redundancy scheme, although perhaps the most typical real-world scenario, is a spare controller on the stockroom shelf, which requires significant technician effort to access, install, and load. This is sometimes called cold standby.
Key redundancy considerations
End users investigating HA and controller redundancy must ensure that any solution satisfactorily addresses four key areas:
- deterministic switchover
- geographically diverse controller installation locations
- ability to upgrade hardware and firmware revisions without downtime
- secure native communications.
Deterministic switchover: Deterministic switchover guarantees that the transition from a failed primary controller to an available secondary controller not only happens within a maximum defined time, but also occurs seamlessly.
Geographic diversity for controllers: Many applications, especially those aboard ships and vehicles, or for very large sites, provide improved reliability if they locate each member of a redundant controller pair as far apart from each other as practical. With this arrangement, a physical failure (like a fire or flood) at one controller location is less likely to impact the other controller location.
Upgrades without downtime: Users need to periodically perform system-level upgrades, such as changing out hardware or updating firmware. Any so-called redundant system that cannot be updated without a shutdown is not truly redundant.
Secure native communications: Security is related in part to the previous upgrade item, because it is almost a certainty that systems will need periodic firmware updates to address cybersecurity issues. Operating systems and software libraries are complex; control and communications functions are more extensive; and system lifetimes are expected to be 10 to 20 years. A redundant controller system can be more cybersecure than a simplex system, but it must rely on secure native communications to safeguard against outside attacks.
Real-world implications
A successful failover can never be too fast. While some processes can withstand disruption or a “hold last state” condition for a few seconds or longer, many machines must failover within milliseconds to preserve acceptable operation. Applications for the management, backup, and distribution of power are prime examples requiring fast failover.
Following are some successful ways that specific redundancy technologies and implementations can meet key requirements, and also some ways they often fail to do so.
Synchronization
Optimal redundancy implementations fully synchronize all data and I/O memory every single scan (figure 4). However, many PLC platforms attempt to synchronize by exception in an attempt to optimize normal operating performance at the expense of allocating enough resources to handle a worst-case event properly. This approach can lead to variable performance on failover and even more drastic cascade-failure problems due to too much data changing at once. Some PLCs must restrict the amount of usable memory by up to one half in order to carry out sync functions.
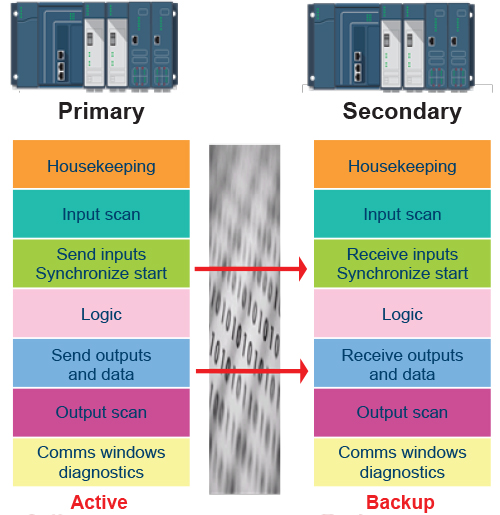
Similarly, primary and secondary PLC logic solving should be executed in synchronized lockstep for fast, consistent, and reliable failover. Operating asynchronous redundant PLCs can lead to unexpected application behavior, and those requiring special program arrangements to group I/O for bumpless handling can be difficult to configure.
For the best performance, the synchronization should be carried out over a dedicated network. Some schemes attempt to use the I/O network for the sync task, and therefore compromise performance for both functions. A dedicated sync network may use copper media, but fiber optic media is often available and offers high bandwidth and electrical noise immunity. It can also extend great distances for applications where the controllers are installed far apart.
Full synchronization is certainly critical for robust I/O control, but it also plays a role for supervisory systems. It allows HMIs and SCADA to continue communications with little or no interruption during failover. Some PLC redundancy schemes exhibit an “HMI blind time” during failover where supervisory systems are unable to read/write PLC tag data, an inferior approach.
Communications
For redundant systems, separate I/O networks are rings themselves, both for high availability and so each controller of the redundant pair can interact with all devices. These fieldbuses, such as PROFINET, should be natively available within the PLC or edge controller ecosystem because relying on a gateway introduces an additional failure point.
The communication protocol from redundant PLCs to higher-level systems is also important. OPC UA has emerged as the preferred choice in this role for several reasons:
- Redundancy provisions: OPC UA includes two types of redundancy in the specification.
- Industrial capability: OPC UA is extensible and incorporates features for contextualizing data, making it a universal language for communicating between all sorts of industrial devices.
- Security: OPC UA provides security in the form of encryption and authentication to help protect industrial systems from outside influences.
However, some PLCs do not support OPC UA in redundant systems and therefore lack these benefits.
Maintenance
It is one thing to experiment with a redundant configuration on the workbench, and quite another to deploy one to the field where it needs to run nonstop for decades. In the real world, parts sometimes need replacing, connections fail, and firmware must be upgraded.
The last point is more important than ever. In past years, many PLCs were installed and never upgraded again as long as they remained functional, a feasible approach because they were largely standalone islands of automation. However, today’s PLCs are heavily networked to external systems, exposing them to cybersecurity threats. Periodic firmware upgrades are more necessary than ever to update systems and improve their cybersecurity, and to provide other features.
Redundant PLC platforms are easiest to maintain if the hardware, firmware, and software versions are not specifically required to match. Unfortunately, many redundant PLC implementations require exact matches, even to the extent of needing a system shutdown to perform firmware upgrades, or in the worst case, triggering a shutdown upon mismatches.
The right controller redundancy combination
As with any effort, the costs of designing, procuring, implementing, and supporting a redundancy solution must be tallied. Certainly, a second controller is necessary, although this is often costed into the work as a spare part anyway. Redundant controllers require additional power supplies, networking cards, cabling—and even entire control panels in some cases. Design and installation efforts can escalate.
Beyond these relatively straightforward costs, users need to consider the impacts on software, licensing, and configuration labor. Some implementations require specialized software versioning, additional licensing costs, and careful programming practices to function. Other systems may only require a few configuration clicks to add redundancy at any time, even after a simplex system is already deployed (figure 5). 
Many vendors offer basic HA redundancy by just adding one more controller, where only the changes are synchronized and there may be a nondeterministic failover time. This is the case for many types of basic PLCs and edge controllers. Some redundancy schemes may place limitations on the number of I/O, field devices, or tag counts.
A more robust configuration incorporates the following characteristics:
- Primary and secondary controllers.
- Each controller in its own rack or location, with a dedicated synchronization communication card using fiber optics, allowing the racks to be located as far as 10 km apart.
- Each rack powered with an independent UPS or other HA power provision, to provide power diversity.
- Complete primary-to-secondary memory synchronization every scan, providing deterministic failover and avoiding HMI blind time.
- Some field device count limitations are acceptable, but full memory and I/O counts must remain available.
- Availability of native use ring-based fieldbus for I/O, such as PROFINET.
- Availability of native secure OPC UA for connectivity to higher-level HMI and SCADA systems.
- Check-box configuration to enable redundancy, with no special PLC or HMI programming needed.
- Ability of users to mix and match hardware, software, and firmware versions at will, and perform upgrades as needed (although maintaining consistent versions is always recommended). The key is to have a matching data synchronization list on both controllers.
Redundant PLC solutions as described in the bullet points above are available and are the best way to deliver true HA for industrial automation platforms. Unfortunately, not all solutions have these capabilities, so buyers must beware.
Comprehensive redundancy is a reality
Industrial controller redundancy has been available for many years, but cost and complexity reserved it for only the most demanding applications. Controller redundancy can now be implemented simply and cost effectively, making it feasible and practical for many more factory automation and machine control applications.
But simply choosing redundant-capable products is not good enough, because there are many implementation details that can erode effectiveness. Nondeterministic failover schemes and nonsecure communications are not suitable for many applications. In particular, if a redundant system must be stopped for any length of time to upgrade user applications, hardware, or firmware, then the promise of HA is broken.
Once users understand critical controller redundancy design details and strategies, they can make an informed decision and select PLC hardware, software, and networking technology to overcome these challenges and deliver a comprehensive HA controller redundancy experience. With minimal additional hardware investment, sometimes nearly equivalent to the amount of spares that would be ordered anyway, end users can select and easily configure a controller redundancy platform that has the best possible performance.
All figures courtesy of Emerson.RESOURCES
“Edge analytics speed optimization cycle times”
"Solving big data problems with a little data approach”
“Better performance begins at the edge”
Reader Feedback
We want to hear from you! Please send us your comments and questions about this topic to InTechmagazine@isa.org.